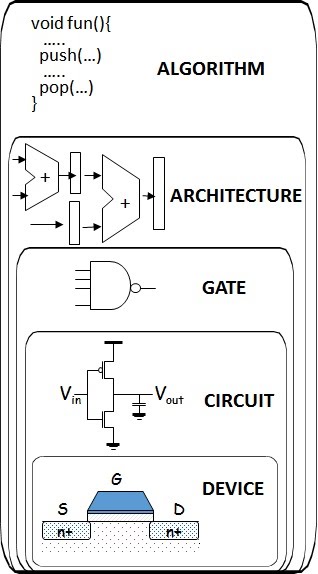
人工智慧與機器學習之軟體硬體共同設計及異質加速運算
(Software-Hardware Codesign and Heterogeneous & Accelerated Computing for Machine Learning) (2020 年進行中之多年期計畫)
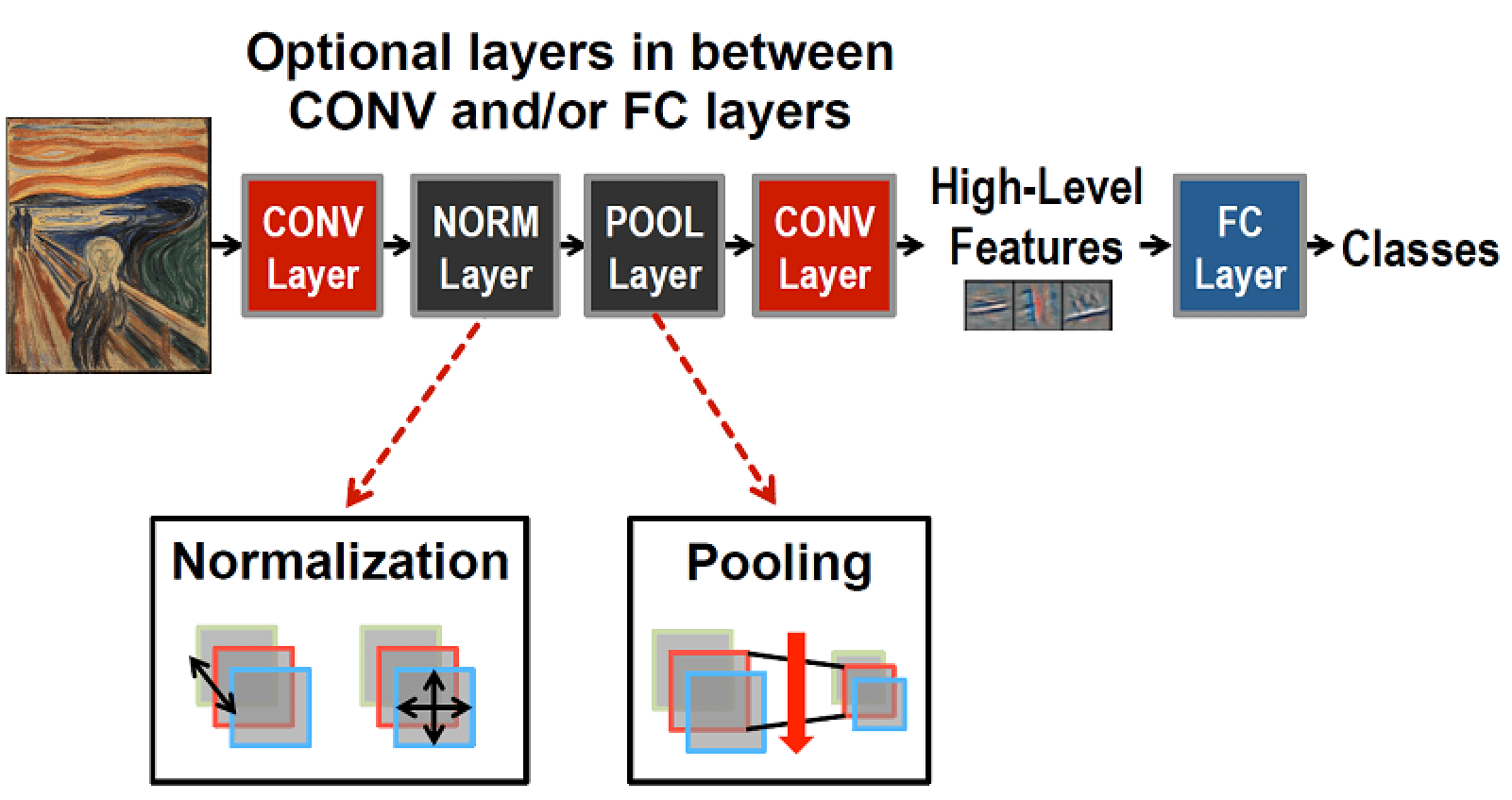
機器學習(Machine Learning) 尤其是深度學習已經在許多應用如物件分類、物件辨識、人臉辨識等中得到極大的成功。常見深度學習網路的架構如下圖。輸入資料經過多個層(Layer) 的運算 (包括卷積層的Convolution 運算,Normalization Layer,Pooling Layer運算等運算) 之後會得到High-Level Feature,之後再經由Fully Connected Layer 會得到結果。
而為為了得到更好的成果及準確度,深度學習類神經網路所須的層數愈來愈多,如LeNet-5的2層Convolution Layer,VGG-16的16層Convolution Layer數目,到ResNet的152 層,
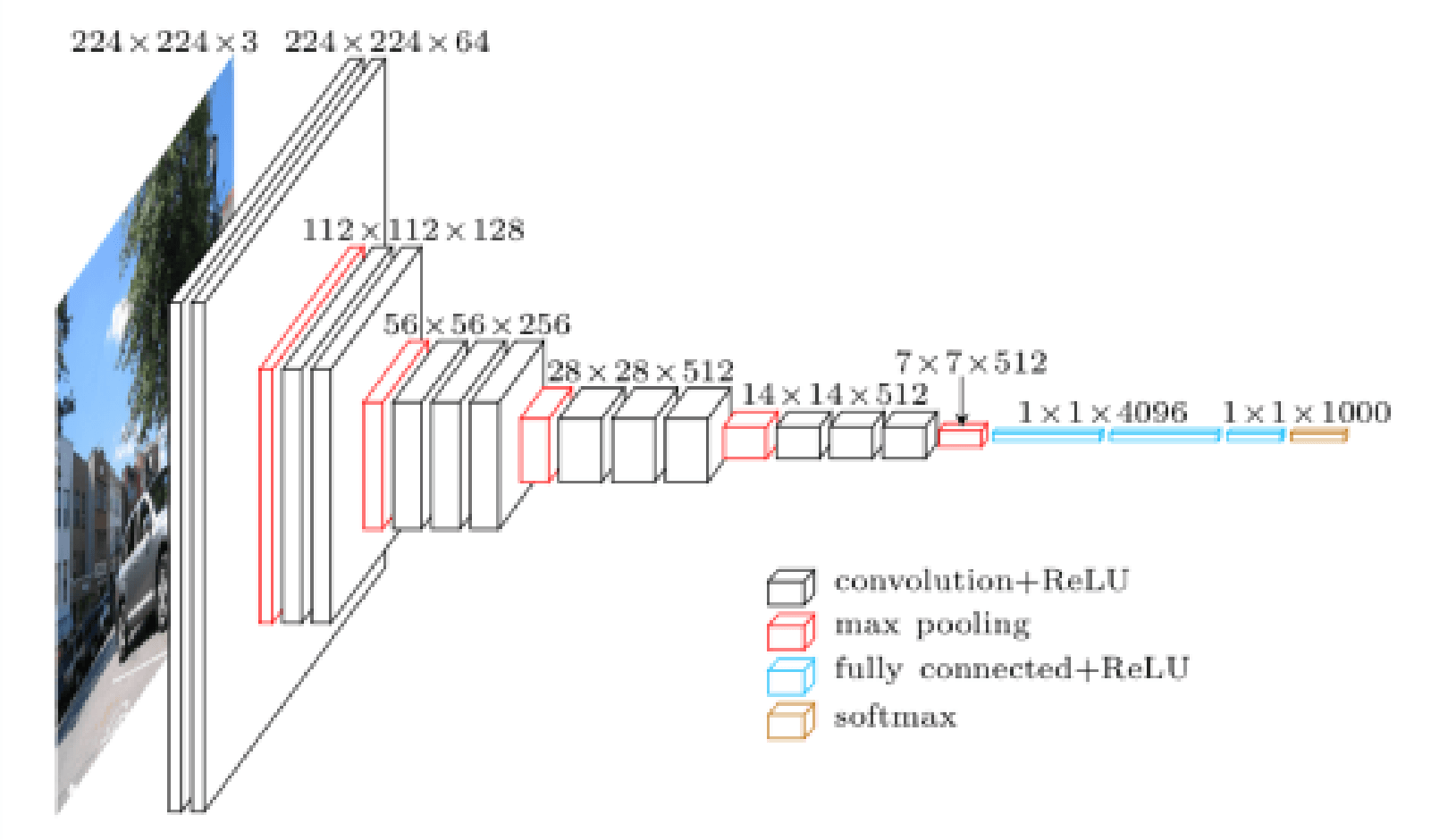
同時深度學習的所需的運算,尤其是Convolution 運算量也愈來愈龐大,從LeNet-5 的341,000次運算,到ResNet的3,900,000,000次運算,深度學習所須的運算呈指數方式增加,如何有快速有效完成運算,是重要的問題。而另一方面,在現今巨量資料時代,深度學度的資料也愈來愈龐大,深度學習的運算所須的記憶體空間也愈來愈龐大。因此如何有效使用記憶體空間,也是極待解決的問題。
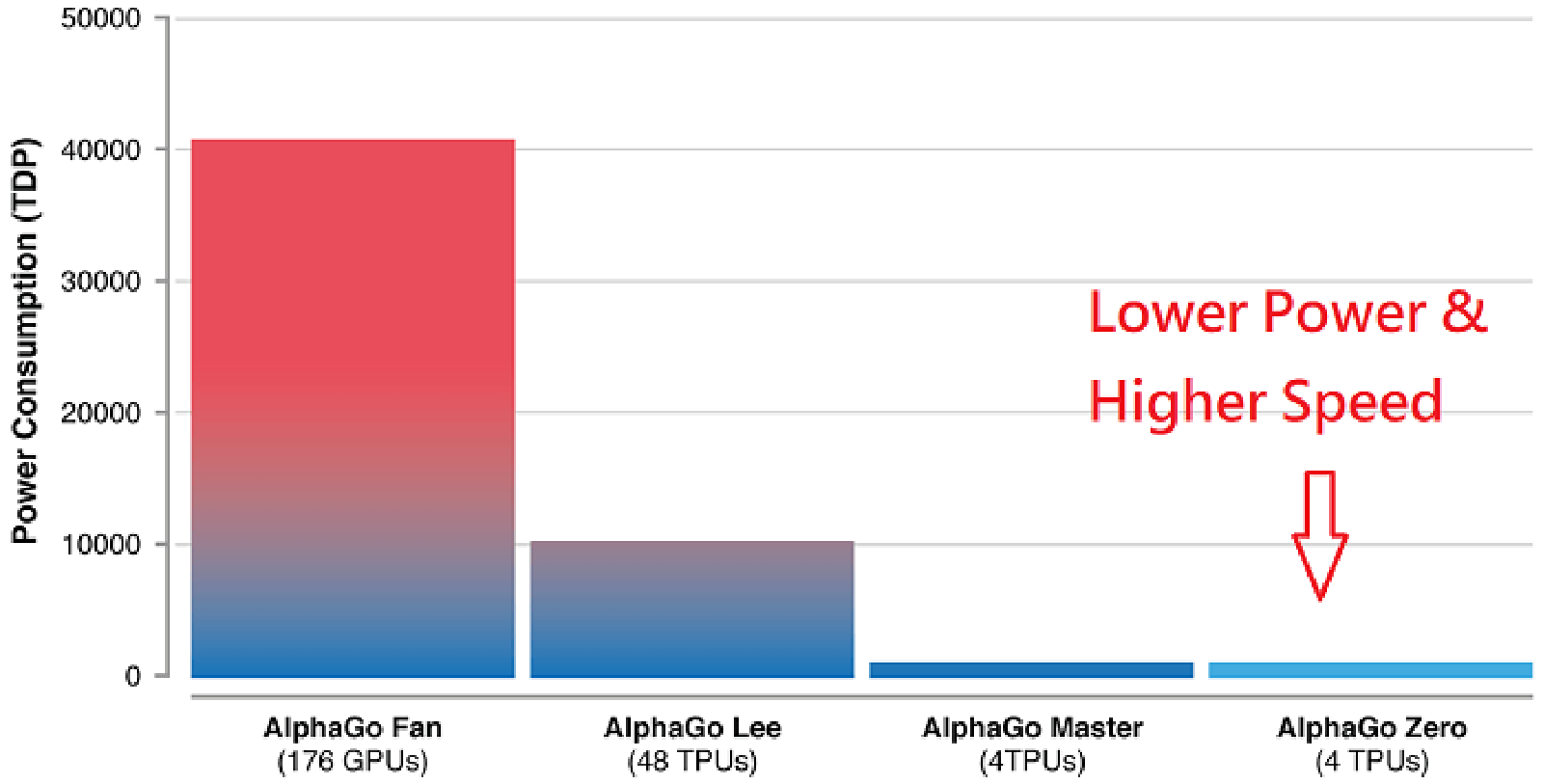
下圖是不同版本的Alpha Go,從最早的AlphaGo Fan使用176顆GPU並消耗40,000瓦,到最新的AlphaGo Zero 只使用4顆Tensor Processor Unit (TPU),只使用數百多瓦,而且能夠運算速度更多。
因此,本研究計畫的主要目的便是設計高效能及省電的深度學習電腦架構及電路,以準確、快速、節能省電的方式完成任務。
此外隨著資訊科技的進步,各種運算設備如Intel CPU, ARM CPU, NVIDIA GPU 等種類愈來愈多,也愈來愈普及。然而,各種運算單元皆有自己的指令集、運算架構、記憶體架構、API等,要針對各種計算設備撰寫其軟體相當複雜,因此許多支援各種運算設備的異質運算系統被提出。其中,由Khronons Group提出的異質系統編寫架構:OpenCL(Open Computing Language)是重要之開放標準。只要依照OpenCL的框架編寫程式,就能在不同的硬體平台上順利執行,無須擔心硬體架構差異的問題。
此外,OpenCL強大的地方在於提供平行計算的機制,也就是可基於任務或資料進行分割,將程式分成多個部分,分派給各個核心並同時平行計算,達到高效能的運算能力。這是目前Heterogeneous Computing的開發主流,也是我們目前主要的研究。
本研究計畫也研究機器學習或深度學習的異質運算平台。我們開發符合OpenCL框架的系統技術發展平台,在該平台上發展各種不同的運算核心,其中包含ARM multi-core、GPU及加速電路,並開發相關驅動程式及其runtime系統,讓使用者可以依照不同機器學習及深度學習神經網路的特性及需求,可以在不同運算單元執行,達到快速且省電的目的
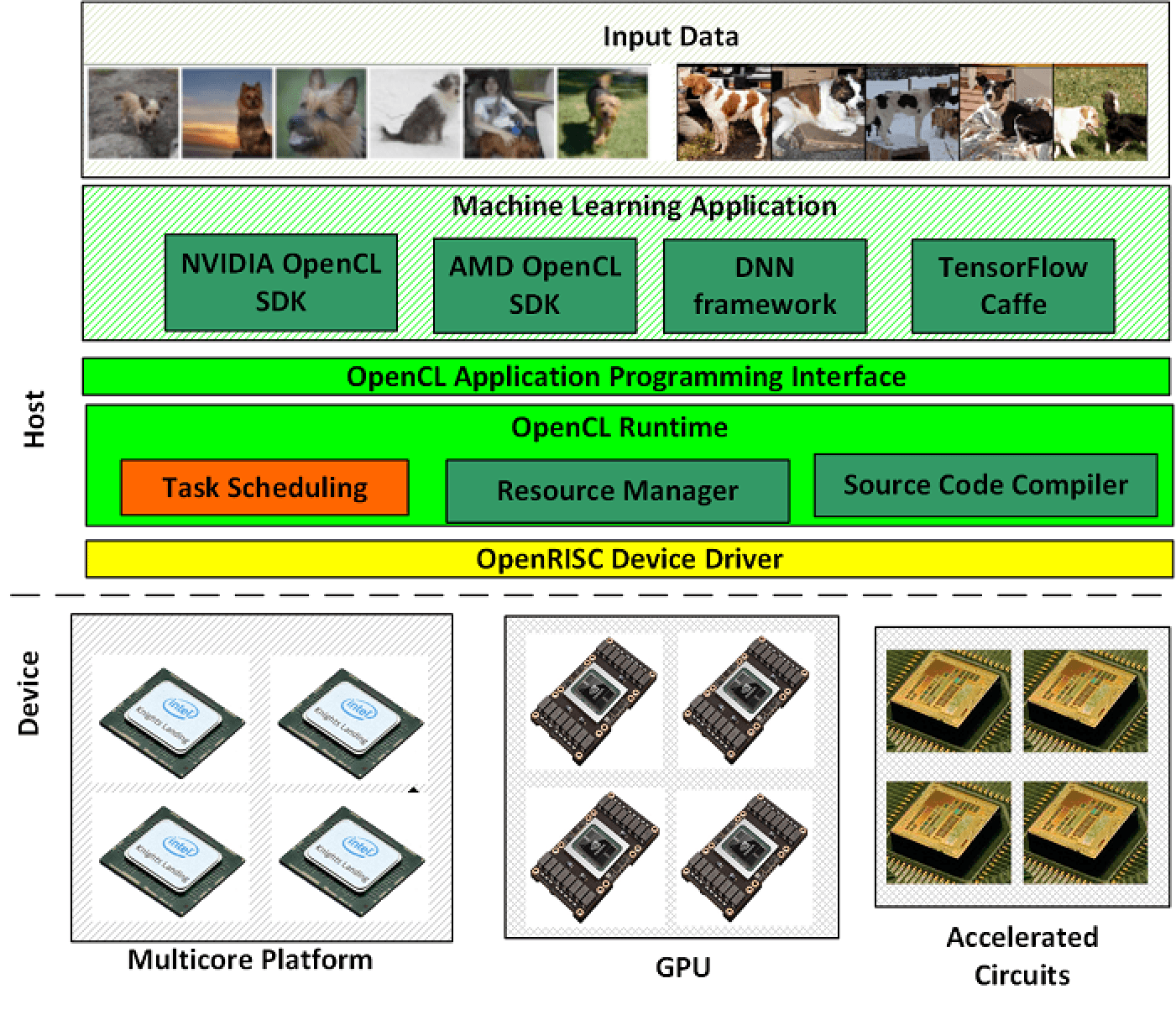
下圖為本實驗室機器學習異質及加速運算平台之架構。最上層的OpenCL Application 層可執行各種深度學習應用程式,透過OpenCL Application Programming Interface (OpenCL API) 和下面的OpenCL Runtime溝通,OpenCL Runtime 部分負責的部分主要是將OpenCL Application層傳送下來程式碼(Source Code)編釋,同時有資源管理者(Resource Manager)及工作排程(Task Scheduler),透過Device Driver將工作傳送到下層各種不同的運算設備(GPU、加速電路及CPU)。
以下為過去科技部異質運算計畫的成果。